
A deep learning, azaz a mesterséges intelligencia önálló tanulási képességének megjelenése kifejezetten látványos eleme volt 2016-nak: hónapról hónapra érték egymást az idegi hálózatokon alapuló képmanipuláló, magától okosodó és képértelmező alkalmazások, gondoljunk csak a Deep Dreamre, a Prismára vagy az Ostagramra.
Az Adobe és a Berkeley Egyetem GVM-nek nevezett közös fejlesztése (Generative Visual Manipulation) egy az egyben úgy néz ki, mint valami, ami hamarosan külön eszközként jelenhet meg a Photoshopban, és szintén idegi hálózatokon alapul. A rendszer mögött álló intelligens generálóalgoritmus a lehető legvalósághűbb képet készíti el, ehhez pedig egyfelől egy forrásképet, másfelől a mi bevitelünket (tehát egérkattintásainkat és -vonásainkat) veszi alapul.
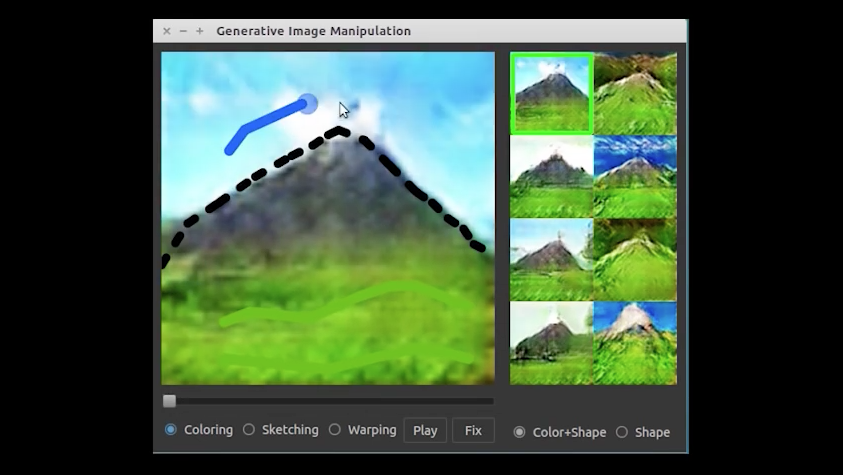
 A fenti képből ez egyértelművé is válik, hogy pontosan mit is jelent, illetve hogy hogyan lesz pár zöld vízszintes vonalból és egy szürke háromszögből komplett tájkép. Megadunk pár alapszínt és egy formát, a rendszer pedig elkezd azon gondolkozni, mi ilyen színű, és mi az, ami így néz ki? Aztán már érkezik is a végeredmény.
A fenti képből ez egyértelművé is válik, hogy pontosan mit is jelent, illetve hogy hogyan lesz pár zöld vízszintes vonalból és egy szürke háromszögből komplett tájkép. Megadunk pár alapszínt és egy formát, a rendszer pedig elkezd azon gondolkozni, mi ilyen színű, és mi az, ami így néz ki? Aztán már érkezik is a végeredmény.
Az algoritmus kifejezetten jól dolgozik olyan forrásképekkel, amelyeknek színét vagy méreteit, illetve formáját kell megváltoztatni. A módszert bemutató videóban láthatóak a méret- és színbeli változtatások (a program ezeket valós időben hozza létre), később pedig a formabeli átalakulások is. Gyakorlatilag morfolásról beszélünk: két képet adagolunk be a rendszernek, az egyik lesz a forráskép, a másik pedig célkép, tehát azt ábrázolja, hogy mihez kellene a forrásképnek hasonlítania.
A program gondolkodik, aztán az idegi hálózat döntéseinek megfelelően elkészíti azt a képet (alábbi példánkban egy táskát), amely kombinálja a két képen látható táskafazonok jellegeit, mindez pedig természetesen emberekkel, lovakkal, épületekkel és bármi mással is hasonlóan működik. Amíg az algoritmus be nem kerül a Photoshopba, addig mi is leszedhetjük és próbálgathatjuk az ezzel kapcsolatos kódrészleteket GitHubról.


